Disene y desarrolle un sistema completo de scraping + analisis de precios con arquitectura de dos capas: una capa de dominio modular con 4 clases (MercadoLibreScraper, PriceDatabase, PriceAnalyzer, utils) y una capa de presentacion con Streamlit de 4 paginas. El scraper usa Selenium con Brave Browser y tecnicas anti-deteccion para extraer datos reales de MercadoLibre. Los datos se persisten en SQLite con esquema relacional append-only, y el motor de analisis calcula estadisticas completas, genera recomendaciones de compra y renderiza visualizaciones interactivas con Plotly. Incluye 4 Jupyter notebooks como documentacion progresiva.
MercadoLibreScraper: clase que lanza Brave Browser via Selenium WebDriver con tecnicas anti-deteccion — deshabilita AutomationControlled en blink features e inyecta navigator.webdriver = false
Deteccion automatica del binario de Brave iterando paths estandar de Windows (Program Files, x86, AppData/Local). Error descriptivo si no lo encuentra
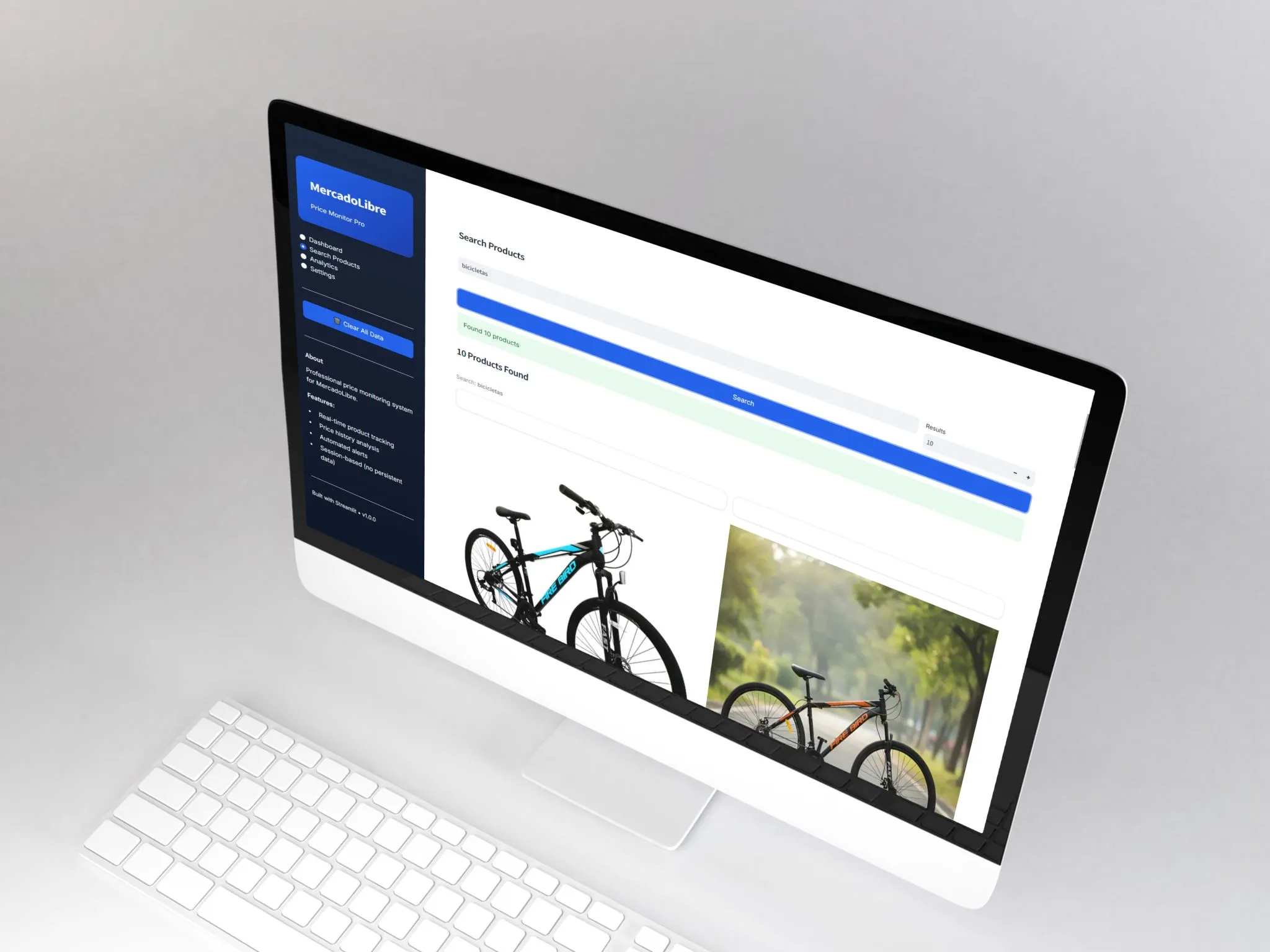
search_products(query, limit): construye URL de busqueda, espera 20s por el selector li.ui-search-layout__item + 3s de sleep para contenido lazy-loaded
Extraccion robusta por producto: id, titulo, precio (float ARS), URL, thumbnail, vendedor, free_shipping (boolean) y timestamp scraped_at
Singleton global _global_scraper que reutiliza la instancia del WebDriver entre llamadas para evitar overhead de 5-10s por busqueda
Context manager para ciclo de vida del WebDriver — close() limpia recursos al finalizar
PriceDatabase: capa de persistencia SQLite con esquema relacional de dos tablas — products (catalogo maestro con first_seen) y prices (serie temporal append-only con foreign key)
Indices automaticos en product_id y scraped_at para queries de historial optimizadas. Upserts idempotentes con INSERT OR IGNORE
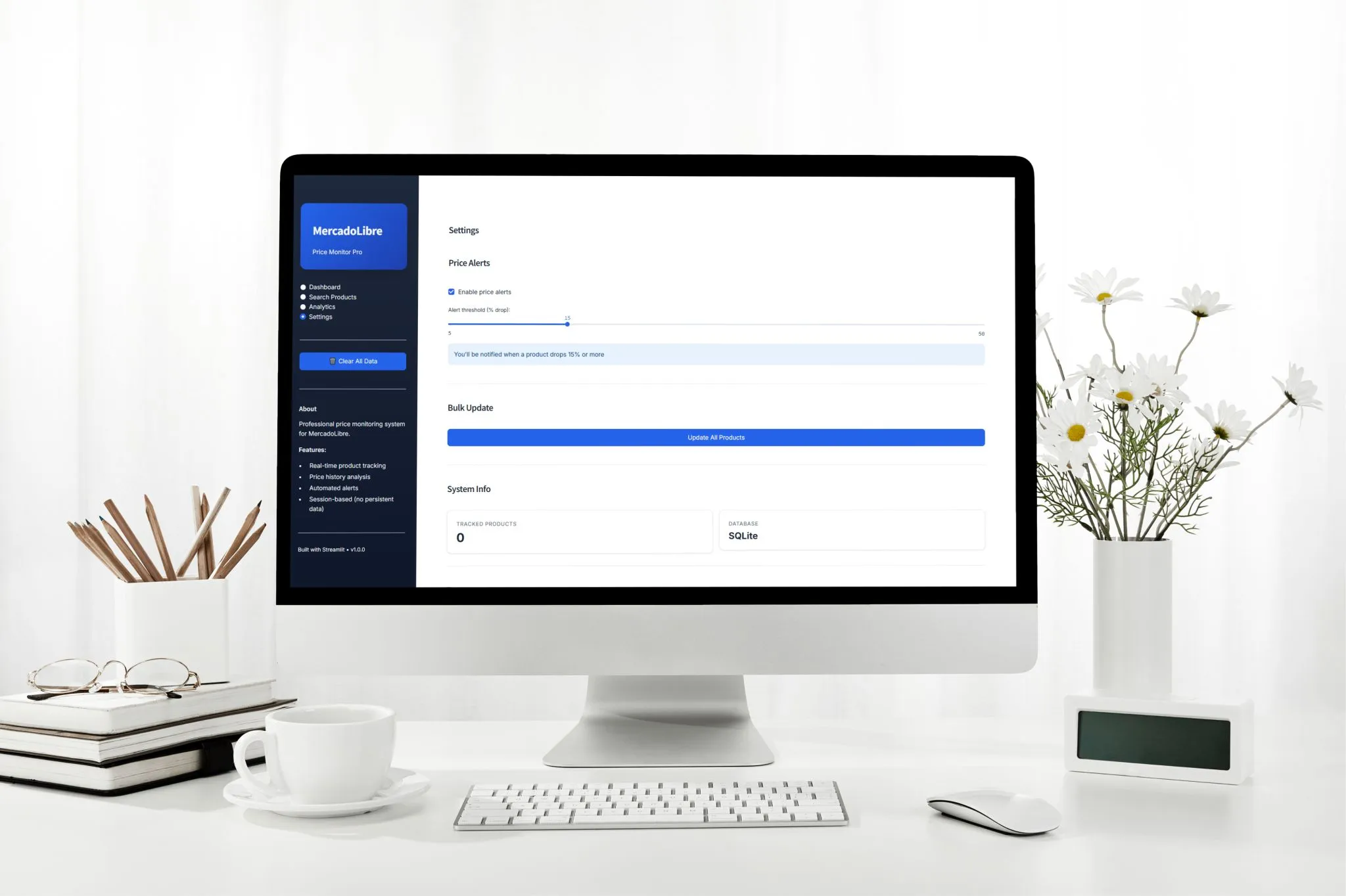
check_alerts(threshold_percent): compara el ultimo precio con el penultimo y detecta caidas significativas por umbral configurable
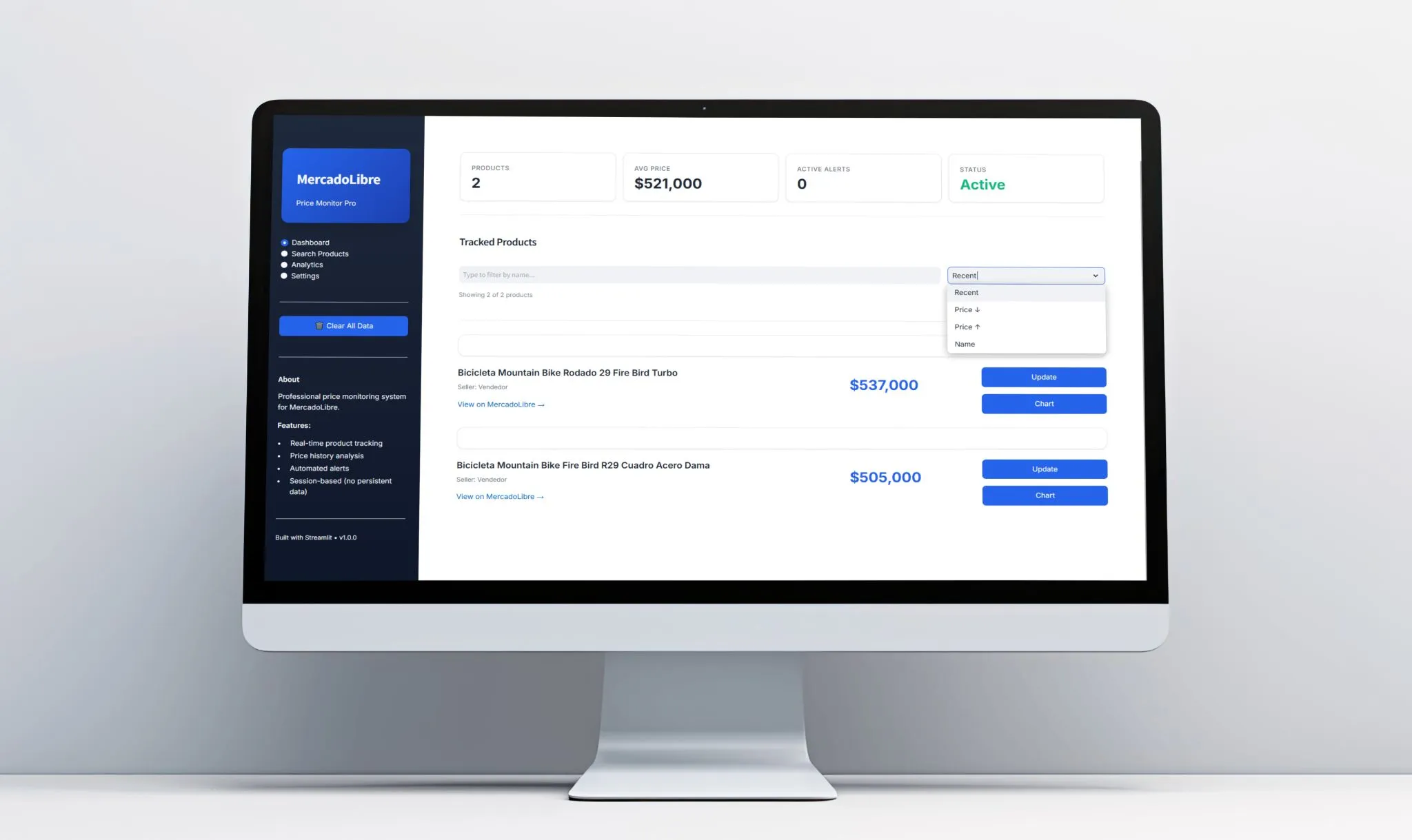
get_stats(): metricas agregadas de la base de datos — total productos, total snapshots, ultima actualizacion
Directorio de datos auto-creado con os.makedirs(exist_ok=True). sqlite3.Row factory para acceso por nombre de columna
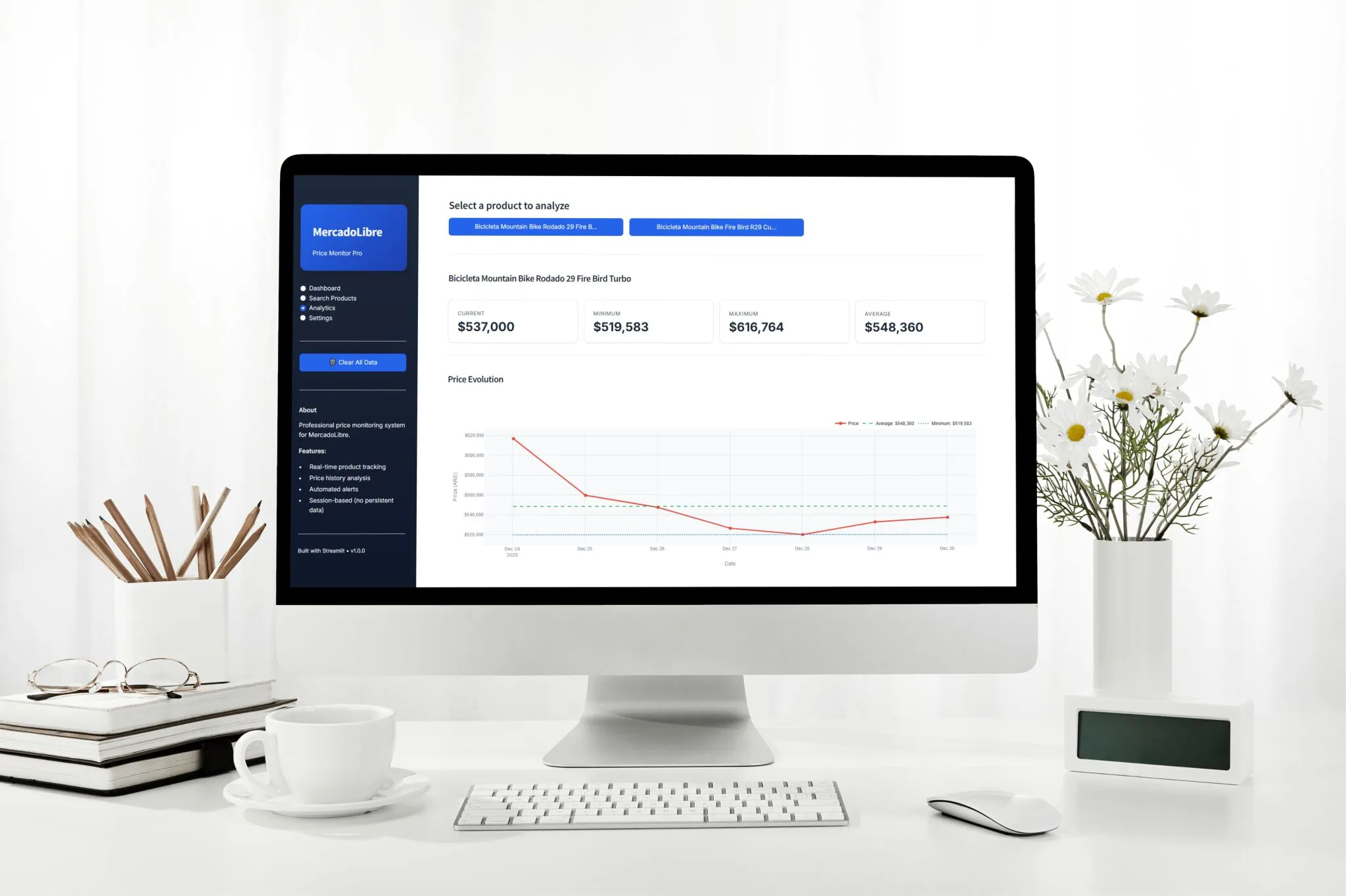
PriceAnalyzer: motor estadistico que recibe historial de precios y calcula min, max, promedio, mediana, desviacion estandar, variacion porcentual ((ultimo - primero) / primero * 100) y total de registros
get_buy_recommendation(): logica de recomendacion de compra basada en tendencias historicas — compara precio actual vs promedio y minimo para sugerir esperar o comprar
Visualizacion dual: plot_price_evolution() genera graficos interactivos con Plotly (embebidos en Streamlit) o estaticos con Matplotlib/Seaborn (export a PNG)
App Streamlit de 4 paginas: Dashboard (metricas overview + alertas + productos recientes), Search Products (busqueda on-demand con scraping en vivo), Analytics (historial + graficos + recomendaciones) y Settings (umbrales de alertas, config de DB)
Persistencia dual: SQLite para almacenamiento permanente + st.session_state para cache volatil en sesion sin hits a disco
Modulo utils.py: formateo de precios con simbolo de moneda, generacion de mensajes de alerta, export de reportes a texto plano, serializacion/deserializacion JSON
config.py: constantes globales de timeouts, reintentos, templates de URL, paths de base de datos y directorios de output
4 Jupyter notebooks como documentacion progresiva: 01_setup_and_test (verificacion del entorno), 02_scraping_basics (busqueda y extraccion), 03_price_tracking (persistencia y alertas), 04_data_analysis (estadisticas y visualizaciones)
Usable como paquete Python: from src import MercadoLibreScraper, PriceDatabase, PriceAnalyzer — instanciar, buscar, guardar y analizar en 5 lineas de codigo
FLUJO — Busqueda y scraping: [Streamlit] usuario escribe "notebook lenovo" en search input → click "Buscar" → [MercadoLibreScraper] reutiliza _global_scraper (singleton) → construye URL: mercadolibre.com.ar/notebook-lenovo → Selenium abre Brave Browser con anti-deteccion (navigator.webdriver=false) → espera 20s por selector li.ui-search-layout__item + 3s sleep para lazy content → extrae por producto: id, titulo, precio (float), URL, thumbnail, vendedor, free_shipping → retorna lista de productos
FLUJO — Persistencia en serie temporal: [Streamlit] recibe productos del scraper → [PriceDatabase] para cada producto: INSERT OR IGNORE en tabla products (upsert idempotente por product_id) → INSERT en tabla prices {product_id, price, scraped_at} (append-only, nunca UPDATE) → cada scraping agrega un snapshot nuevo → con el tiempo se forma una serie temporal de precios por producto
FLUJO — Analisis y recomendacion de compra: [Streamlit Analytics page] usuario selecciona producto del dropdown → [PriceAnalyzer] carga historial de precios desde PriceDatabase → calcula: min, max, promedio, mediana, desviacion estandar, variacion % ((ultimo - primero) / primero * 100) → [get_buy_recommendation()] compara precio actual vs promedio: si actual < promedio * 0.9 → "Buen momento para comprar" / si actual > promedio * 1.1 → "Espera, el precio esta alto" / si ~promedio → "Precio estable" → [Plotly] genera grafico interactivo de evolucion de precios con lineas de promedio y min/max
FLUJO — Alertas de caida de precio: [PriceDatabase] check_alerts(threshold_percent=10) → para cada producto con 2+ snapshots: compara ultimo precio con penultimo → si caida >= 10%: genera alerta {producto, precio_anterior, precio_actual, caida_%} → [Streamlit Dashboard] muestra alertas en cards con color verde y icono de flecha hacia abajo → el usuario identifica oportunidades de compra